Set up
On this page you will find all the elements required to reproduce the elements of the paper "YARBUS:Yet another rule-based belief update system". For any information about what you find in the repository or about the paper, please contact Jeremy Fix @jeremyfix .
First, some general comments, to get all the elements of the repository :
cd your_repo_root
git clone https://github.com/jeremyfix/dstc.git
cd dstc
mkdir build
cd build
------
cmake .. -DDSTC_Viewer=ON && make
--OR--
cmake .. && make // to avoid building the viewer which requires Qt
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./src
// You are ready to play with the tools of the package
You can play around with :
- ./src/statistics which computes statistics given flist input files
- ./src/viewer to explore the datasets and tracker outputs
- ./examples/example-xxxx to play with Yarbus and some other stuff for comparing trackers, filtering out flist, ...
Yarbus
Basic usage
Yarbus is a simple rule based belief tracker you can run on the dialogues from the DSTC2 and DSTC3. In the repository, Yarbus is provided as several scripts :
- examples/yarbus is the tracker, producing the JSON tracker output for the joint goals, requested slots and methods
- examples/yarbus-with-labels is the tracker making use of the labels to compute some statistics on the fly
- examples/yarbus-rule-set is the tracker and you can specify which rule set to use
- examples/yarbus-semantics is the tracker run over the semantics field of the labels, simulating a perfect SLU
Basically, to run the tracker with a threshold of the belief of 0.01 on DSTC2 :
./examples/yarbus ~/DSTC/scripts/config/dstc2_test.flist ~/DSTC/scripts/config/ontology_dstc2.json 0.01 0
./examples/yarbus ~/DSTC/scripts/config/dstc2_test.flist ~/DSTC/scripts/config/ontology_dstc2.json 0.01 1 voip-28848c294
Varying the rule set
In the paper, we varied the set of rules being used. This can be achieved with yarbus-rule-set. You need to specify a rule set defined as an integer that we convert as a binary code for selecting the rules. There are five rules, let us denote the rule set number as r0r1r2r3r4. The ri in {0, 1} indicates if we activate or not a rule with :
- r0 : the inform rule
- r1 : the expl conf rule
- r2 : the impl-conf rule
- r3 : the deny rule
- r4 : the negate rule
As we saw in experiments, most of the score is achieved by activating only the inform and expl-conf rules (i.e. rule number 24) and if, in addition you set the belief threshold to 0.01, so~:
./examples/yarbus-rule-set ~/DSTC/scripts/config/dstc2_test.flist ~/DSTC/scripts/config/ontology_dstc2.json 0.01 0 24
python score.py --dataset dstc2_test --dataroot ~/DSTC/data --ontology ~/DSTC/scripts/config/ontology_dstc2.json --trackfile dstc2_test-output.json --scorefile scores.csv
python report.py --scorefile scores.csv
A port in python
In the repository, there is a python script baseline-yarbus.py which follows the same structure than the other baselines submitted to the challenges. However, be warned that the python script can much slower than the C++ code (because of some inefficient data structures and this slowness is especially true on SLU with a lot of hypothesis). In short, we advise you to use the C++ script. Anyway, as in the C++ script you can specifiy the rule set and the threshold to be used for prunning the belief. For example, prunning at 0.01 and using the expl-conf and inform rule, you would call something like (this call might vary depending on the paths of the data):
python baseline_yarbus.py --rule_set 24 --thr_belief 0.01 --dataset dstc2_test --dataroot ../data --ontology config/ontology_dstc2.json --trackfile yarbus.json
Statistics
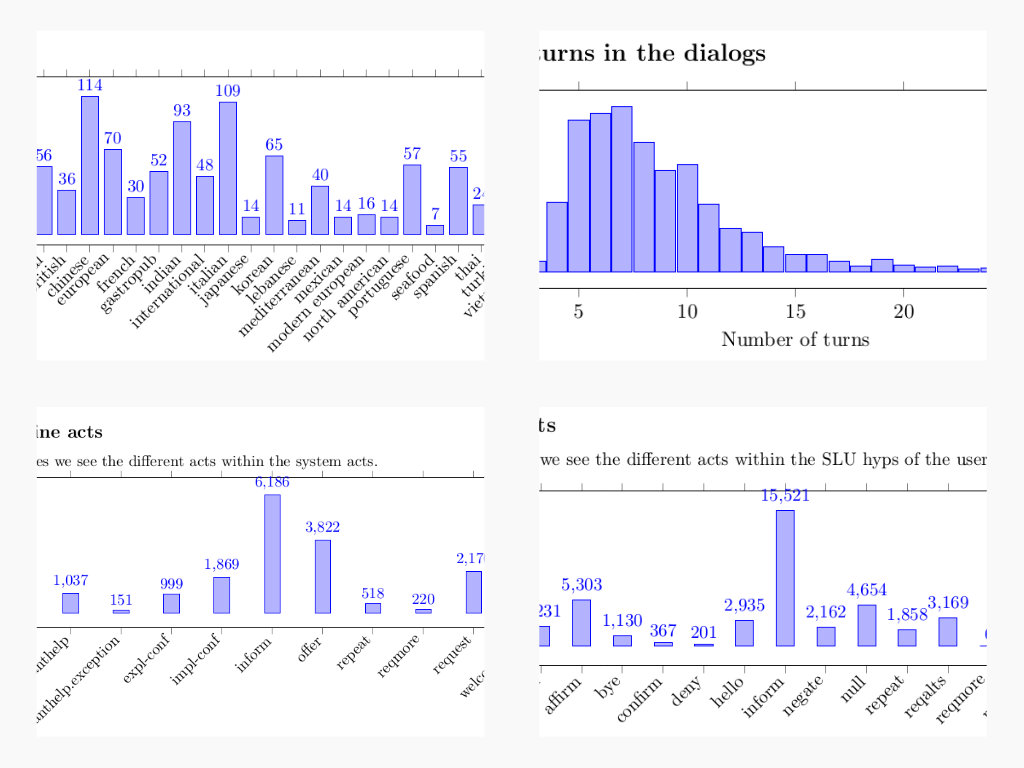
In order to check out which dialog acts are used and with slot/value pairs, you can run the src/statistics scripts. It generates latex outputs ready to be compiled two times with pdflatex. It basically generates histograms on the acts and the slot/value pairs involved.
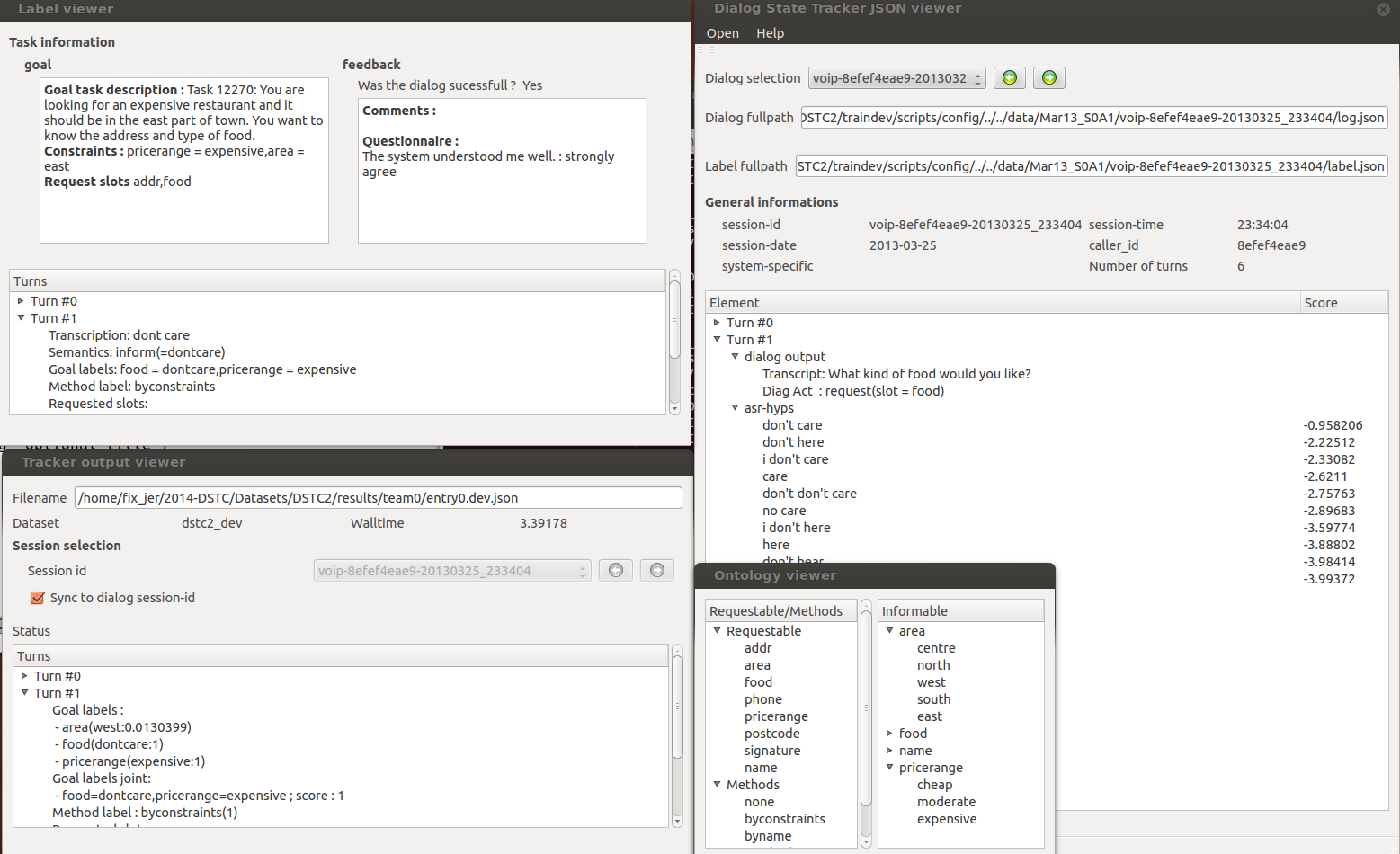
The Viewer
Just launch viewer as src/viewer, load an ontology, dialog filelists, tracker output if you wish and explore the data.