Architecture des ordinateurs
Procédures, pile et langages de haut niveau
2026-07-09
Petit retour sur l’architecture v0

Automate à états finis du séquenceur
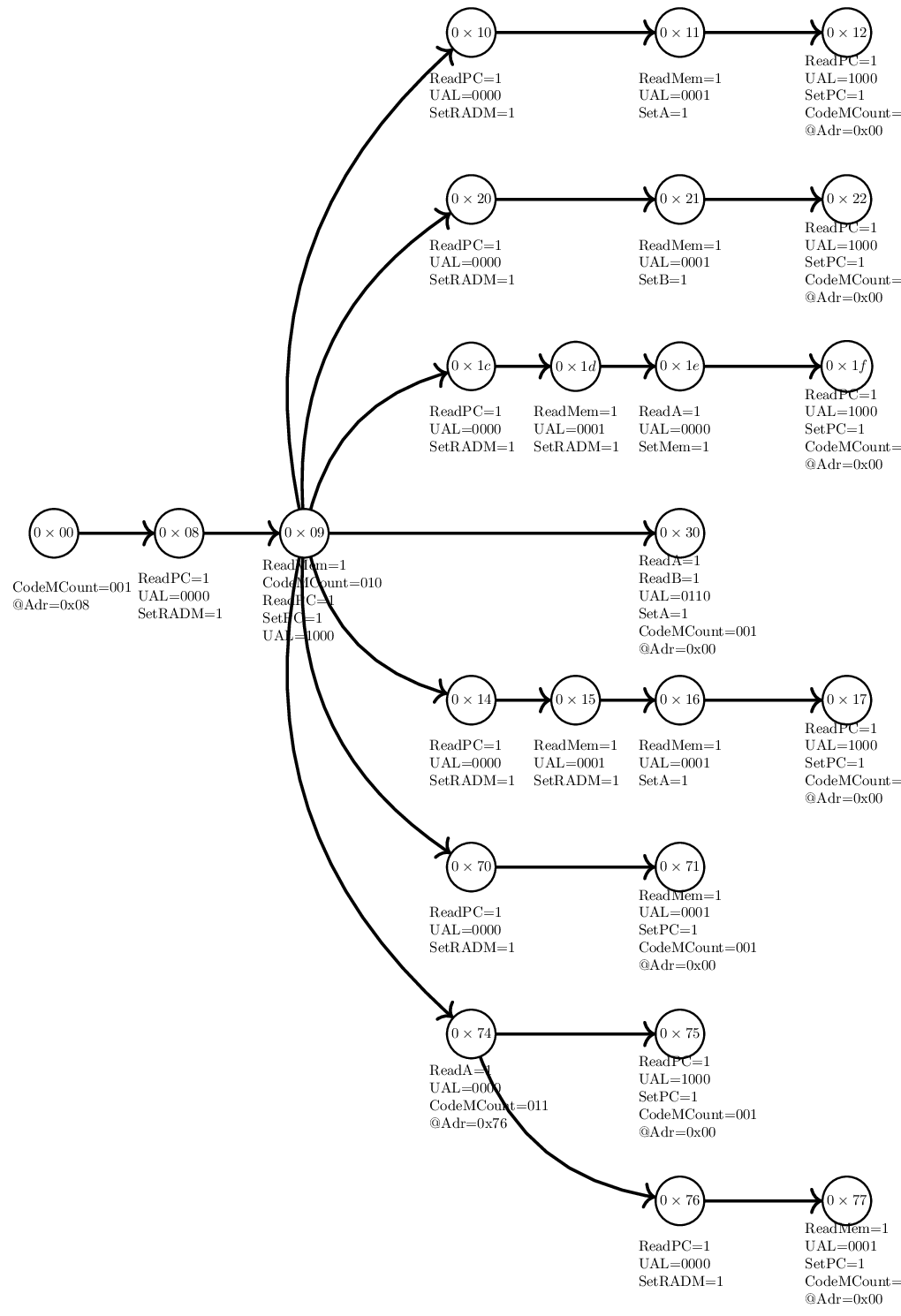
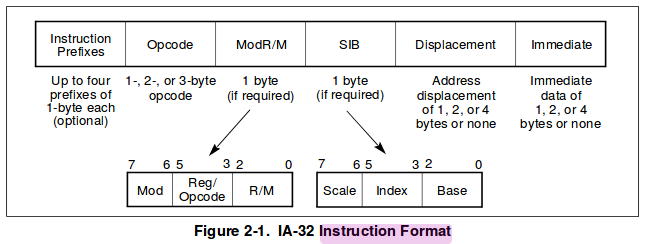
Intel x86 IA32-64
Intel x86 IA32-64
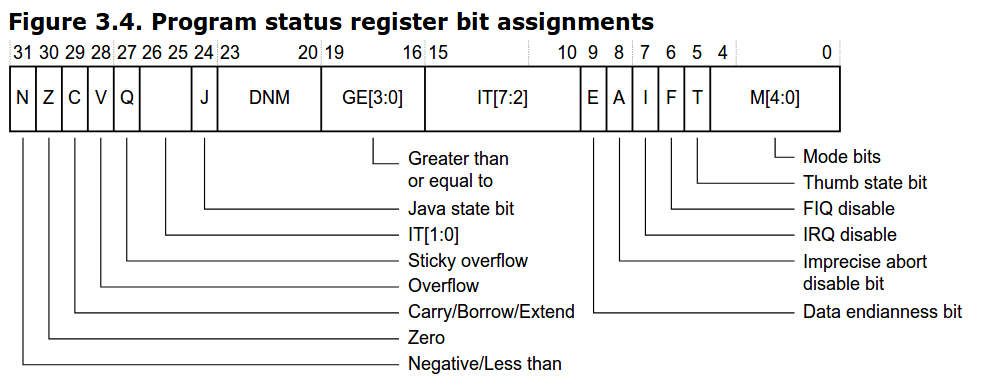
Le registre de statut EFLAGS

Carry Flag (CF), Sign Flag (SF), Zero Flag (ZF),
Intel x86 IA32-64
Beaucoup d’instructions : 1.300 mnémoniques, plusieurs modes d’adressages, ..
Note
Opérations arithmétiques : ADD(0x01, 0x02, 0x03), AND(0x21,0x22, ..)..
Branchements (in)conditionnels: JMP (0xFF), JZ, JNZ, JG, conditions à partir des bits de statut
Lecture/Ecriture : MOV(0x8B, 0xC7, …)
Documentation des instructions https://cdrdv2.intel.com/v1/dl/getContent/671110.
ARM (téléphones, tablettes, consoles)
Note
Le registre CPSR
ARM - Jeu d’instructions
Note
Data Processing avec opcode: AND(0000), ADD(0100), SUB(0010)

Branchements : BX, BL, ..

et bien d’autres…
Chemin de données et programmation
Conception
- Chemin de données
- Jeu d’instructions
- Séquenceur

Programmation
- Code machine (instructions/données)
- Calcul des adresses “à la main”
- adresses des branchements?
- adresses des données ?

Les procédures : illustration
Note

- programme de \(f\) : \(0\times 0014\)
- on utilise ici explicitement le registre A pour stocker les arguments et le résultat
- retour ?
Procédures, pile et pointeur de pile
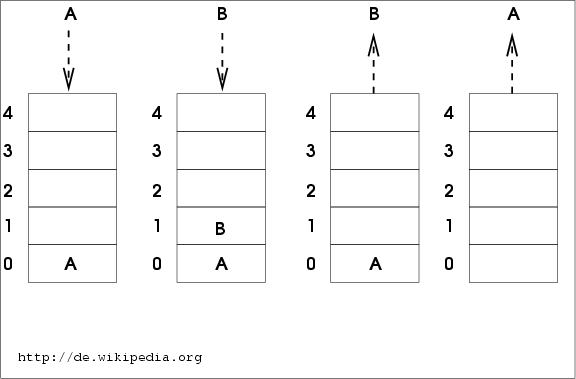
Spécifications d’une pile
Une pile en mémoire
- structure de données en mémoire principale (RAM)
- empiler, dépiler une valeur : sommet de pile
- ou est le sommet de pile : registre Stack Pointer
- le sommet de la pile désigne la prochaine zone mémoire libre
Ajout de SP dans le chemin de données
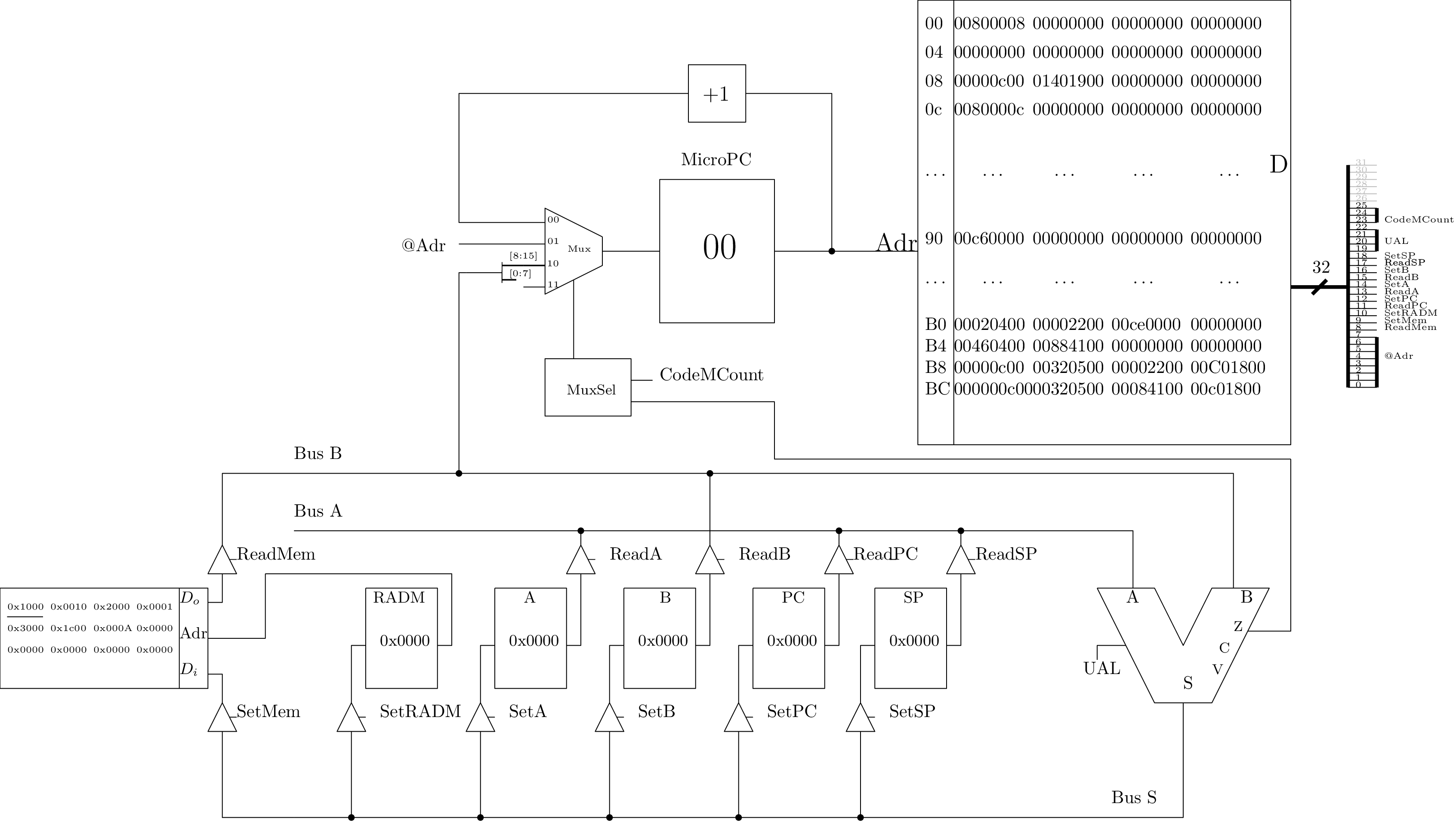
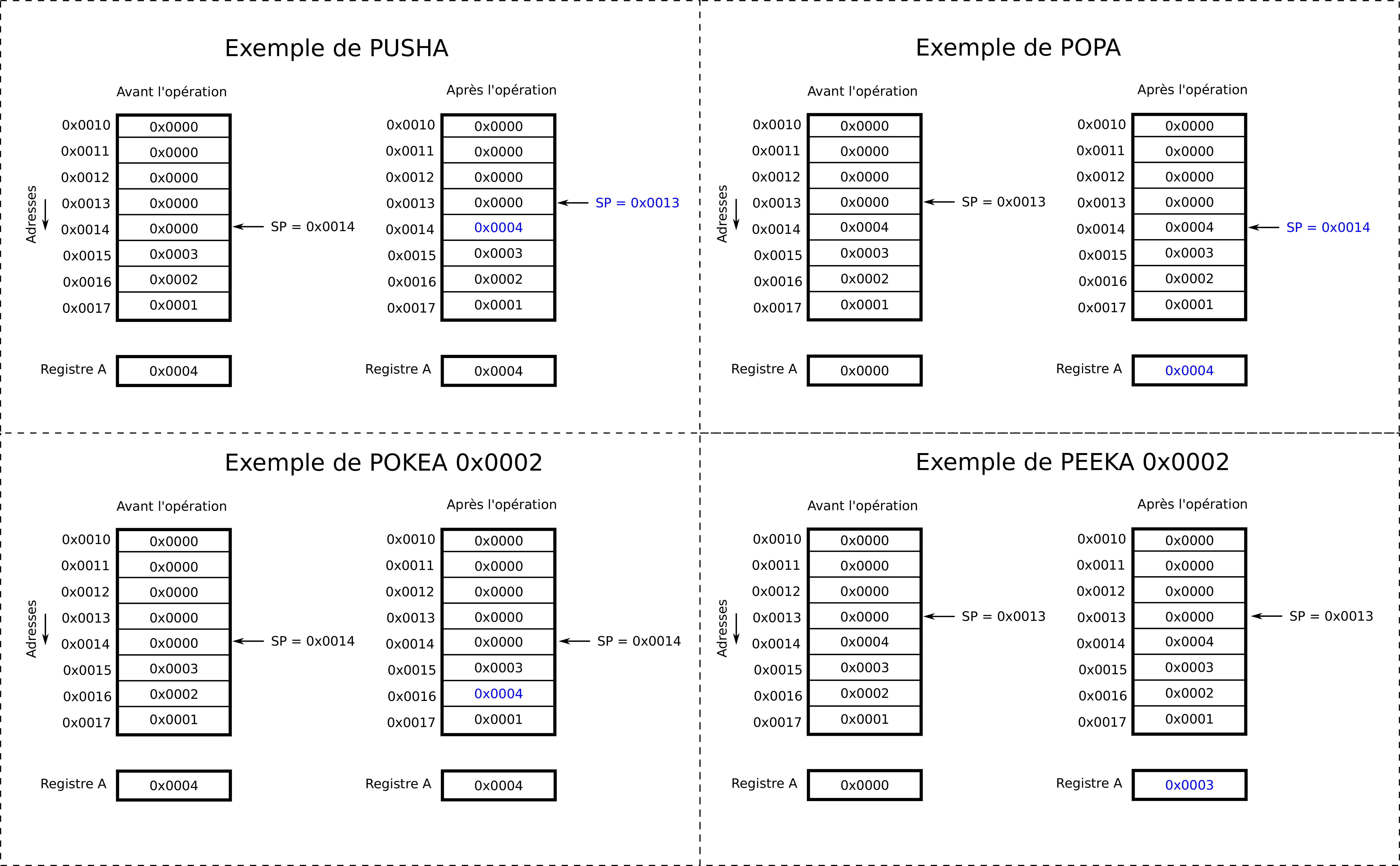
PUSH, POP, POKE, PEEK, Hum?!
→ Machines à états (b0, b4, b8, bc)?
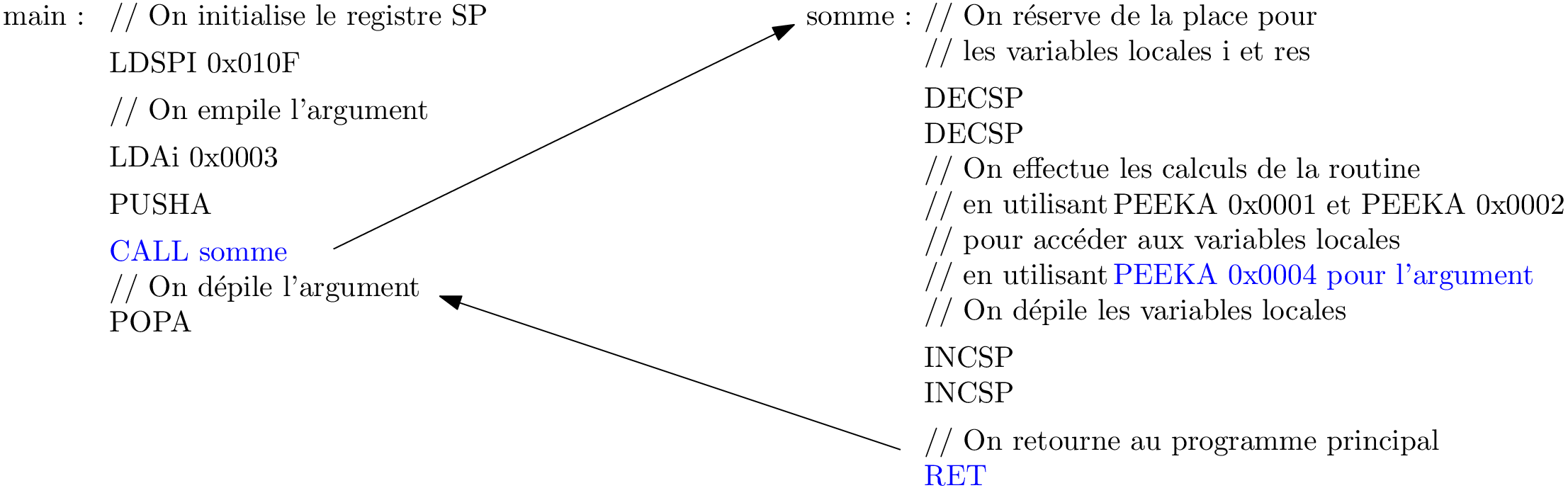
Somme: Une première tentative, juste JMP ?
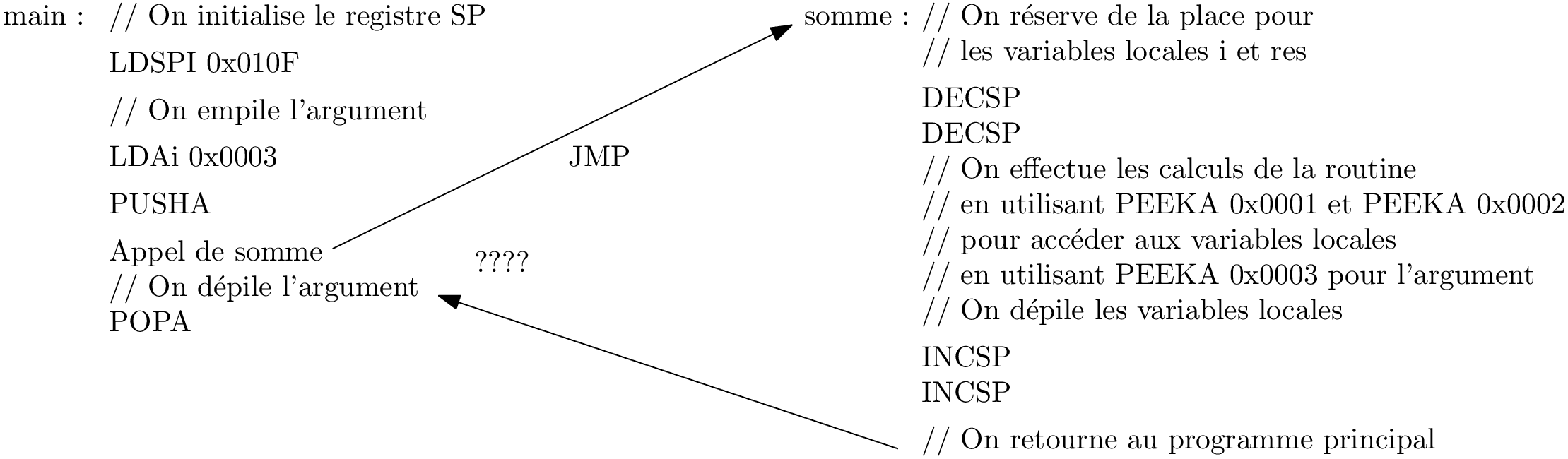
Réalisation de ces instructions
Réalisation de ces instructions
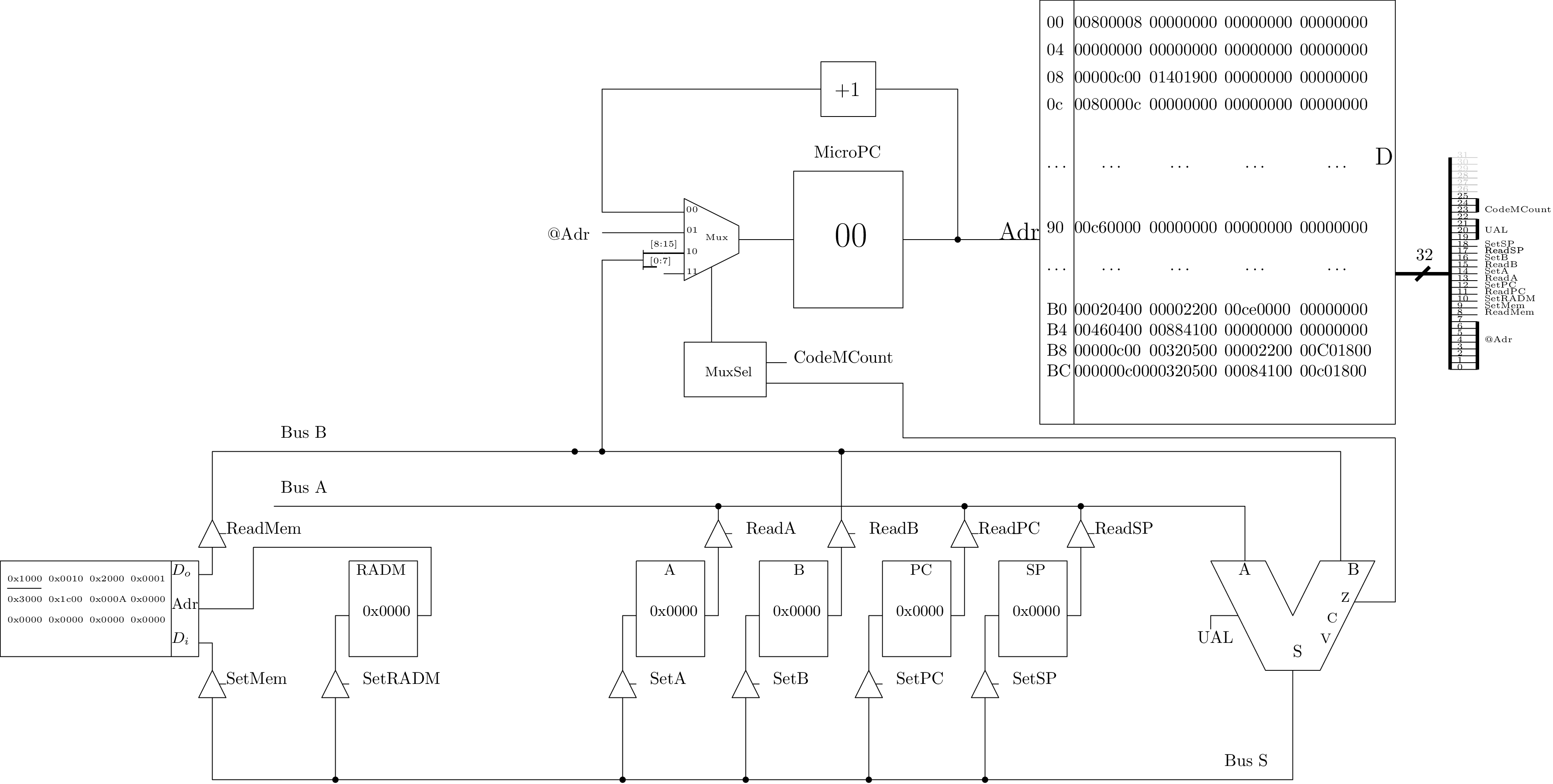
Réalisation de ces instructions
et le résultat au fait? La pile !
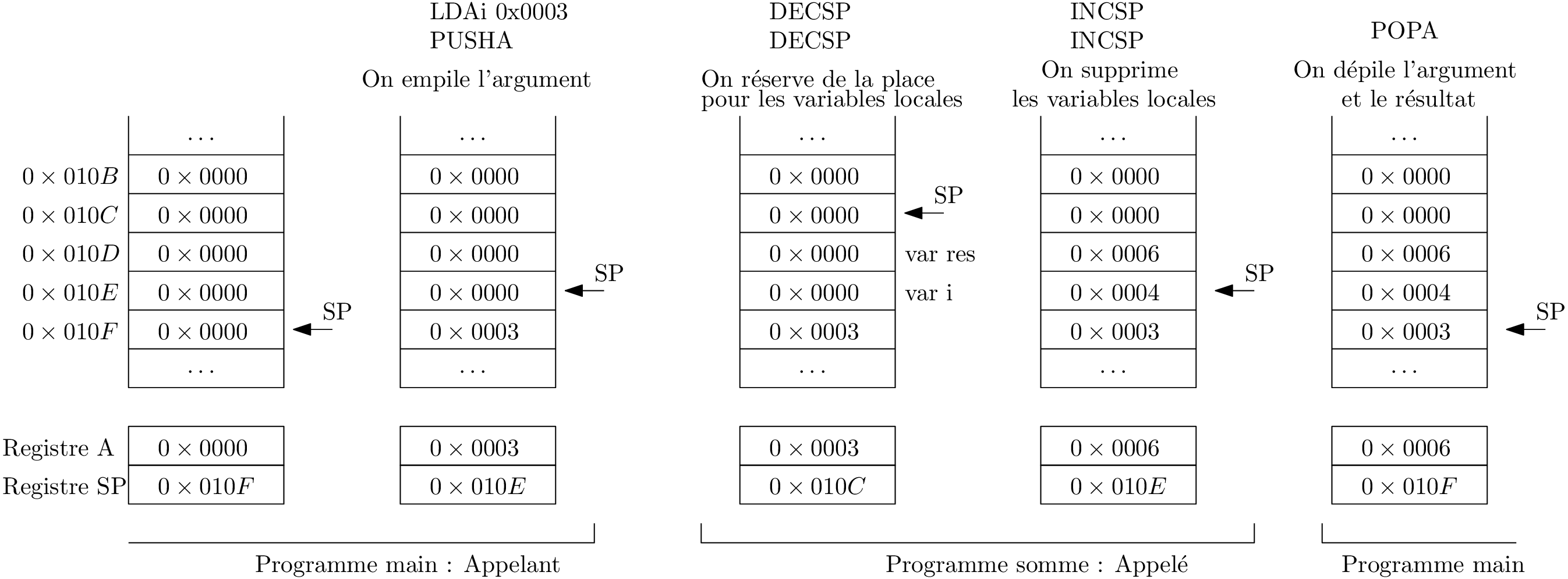
Somme : une deuxième tentative
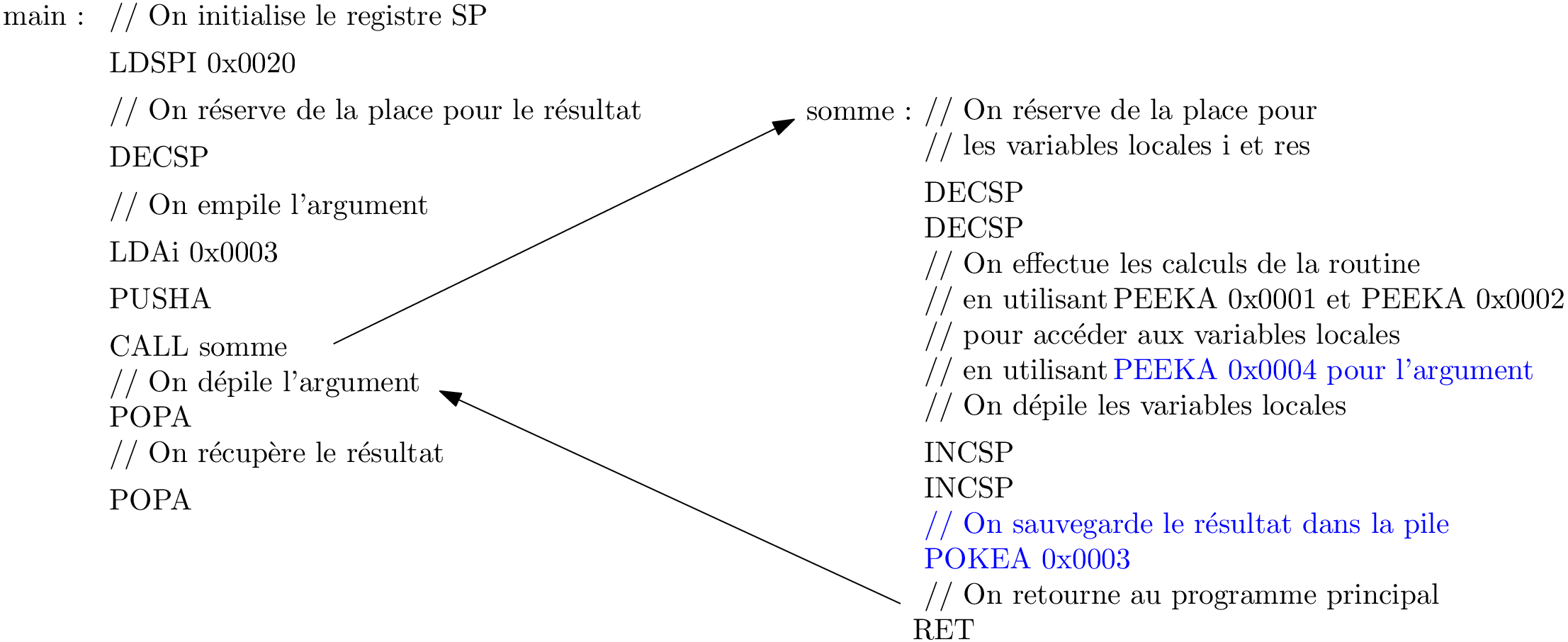
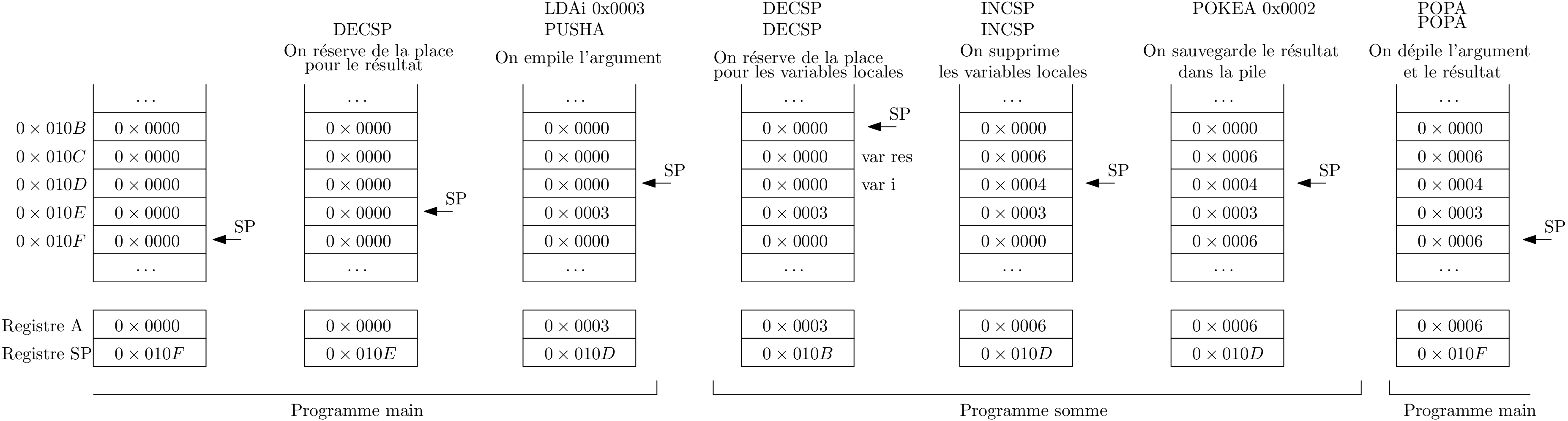
Qui met/enlève quoi dans la pile ?

Attention!
Dans cette version d’architecture, les accès PEEK, POKE sont relatifs au sommet de pile !
Autre possibilité : registre Base Pointer (BP) / Frame Pointer (FP)
Pour restaurer le registre SP, on pourrait aussi utiliser BP/FP
Des fonctions récursives : Hanoï

Problème
Calculer le nombre de déplacement minimum nécessaires : \[h(n) = \begin{cases} 1 & \mbox{si } n=1 \\ 2h(n-1) + 1 & \mbox{sinon} \end{cases}\] \(h(4) = ?\)
Exercice : Définir le code assembleur pour calculer \(h(4)\).
Exécutons (à 8 Hz) et regardons le contenu de la pile pour visualiser les contextes.
Des fonctions récursives : Hanoï

La pile pourrait “déborder” \(\rightarrow StackOverflow\)
Au fait ..
Comment passer de la formalisation du problème à un algorithme efficace permettant de le résoudre ??
Cours SDA (1A - S06): Structures de Données et Algorithmes
Cours C++ (1A - S06): Programmation C++, structures de données, etc…
Cours Génie logiciel (2A - S07): Etude des méthodes et bonnes pratiques pour le développement logiciel
La couche d’assemblage
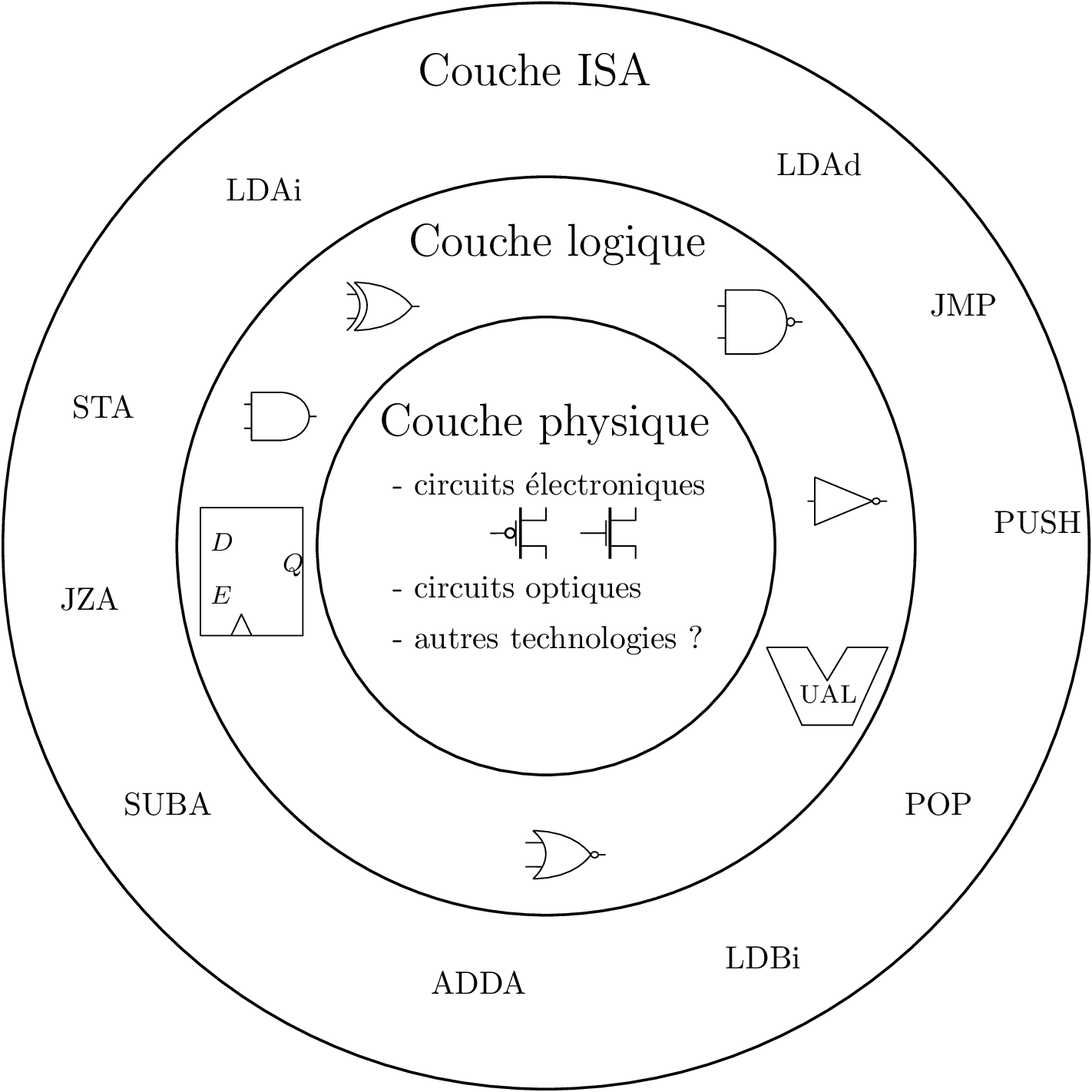

Langage d’assemblage et assembleur
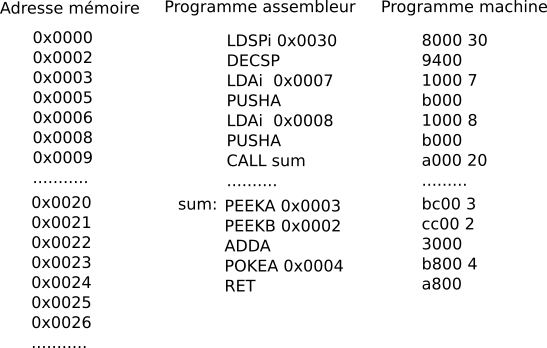
Assembleur : programme traduisant langage d’assemblage → code machine.
Abus : programme assembleur = programme en langage d’assemblage
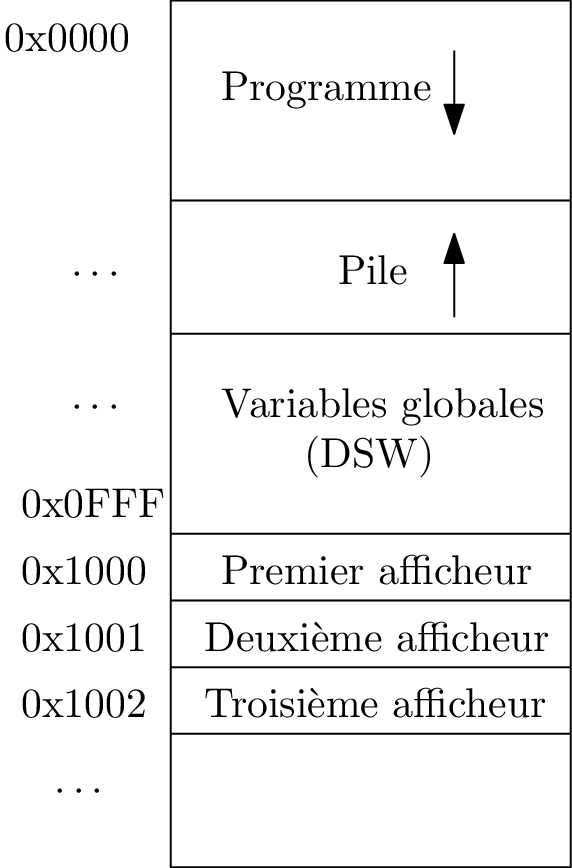
Disposition du programme et des données en mémoire (chez nous)
Langage de haut niveau (Python, C, C++, Scala, ..)

Mais pourquoi ?
Assembleur
- spécifique à une architecture
- encore dur à programmer (
LDAd b; LDBd c; ADDA; STA a) - peu de vérification syntaxique: on peut ajouter des choux et des carottes
Langage de haut niveau
- indépendant de l’architecture
- langage plus intuitif, e.g. \(a = b + c\), structures de contrôle, définition de fonctions
- vérification syntaxique
Brève Anatomie d’un compilateur

Références :
- “The dragon book” Aho, Lam, Sethi, Ullman
- “Modern Compiler Implementation”, A. Appel
La phase d’analyse (frontend)
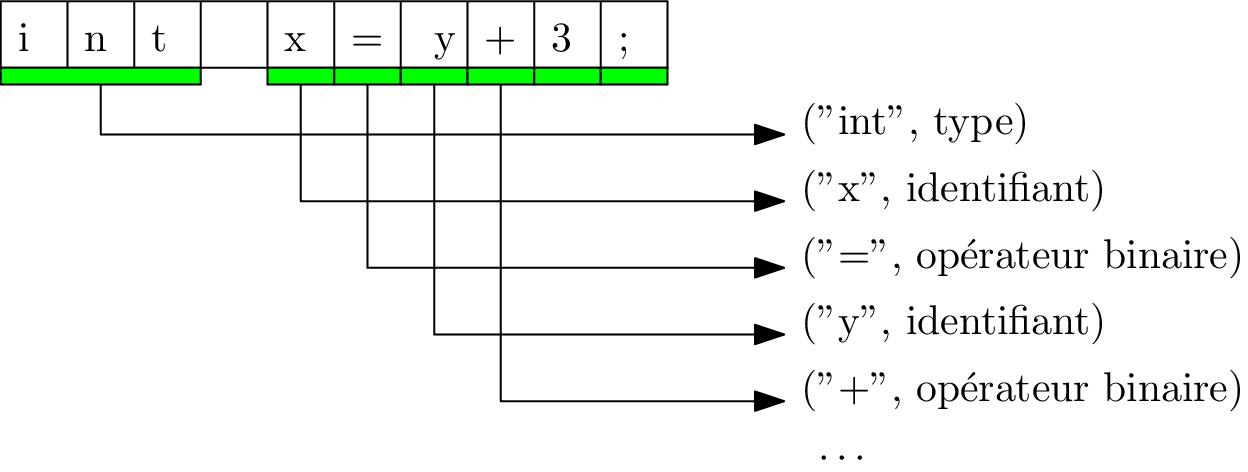
Analyse lexicale
Ségmentation et identification des lexèmes
Analyse syntaxique
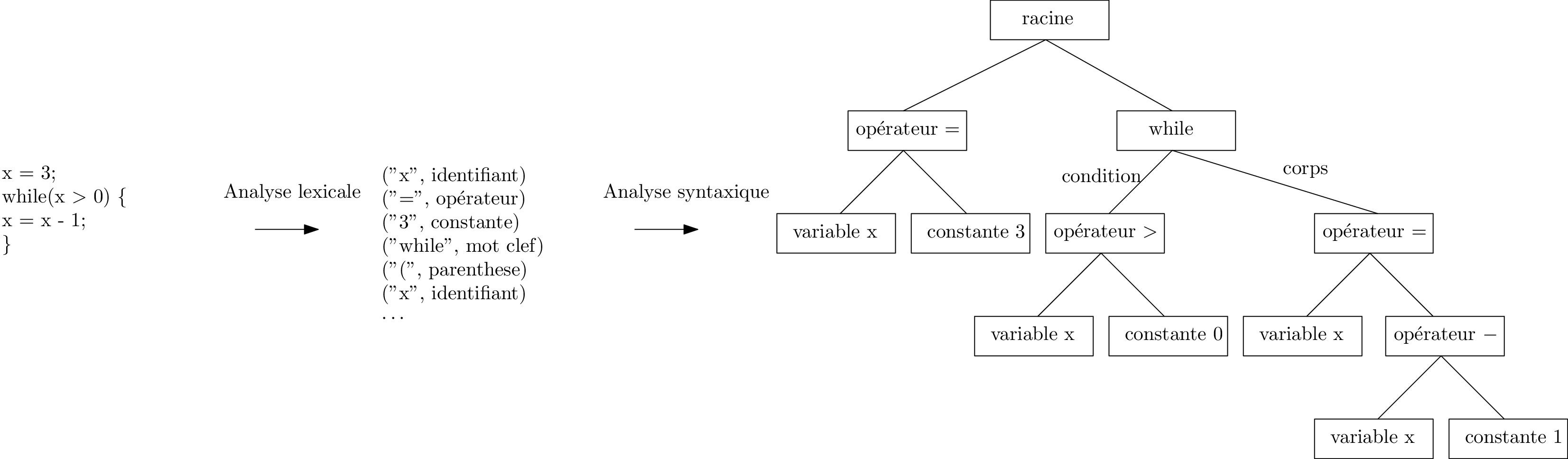
Construction d’un arbre syntaxique à partir des lexèmes et d’une grammaire du langage.
La phase d’analyse (frontend)
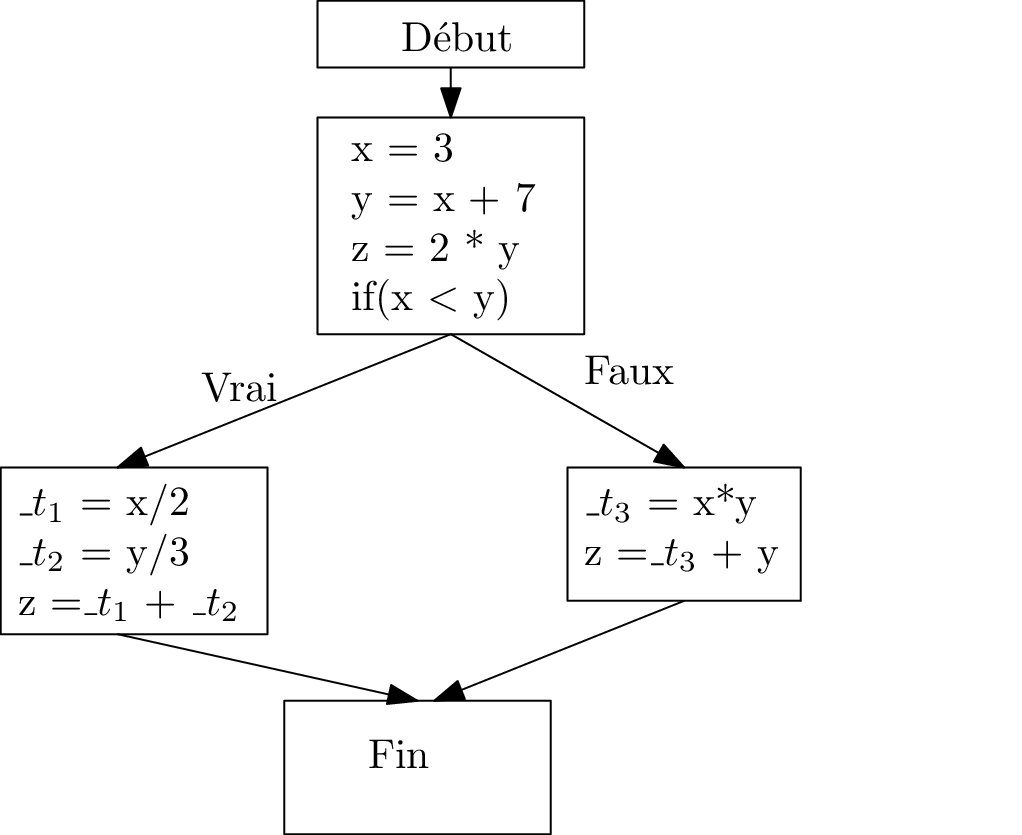
Exemple de représentation intermédiaire : Three Adress code
En C++ :
Représentation 3-Address Code
x = 3;
_t1 = 2 + 7;
y = _t1 + x;
z = 2 * y;
_t2 = x < y;
IfZ _t2 Goto _L0;
_t3 = x / 2;
_t4 = y / 3;
z = _t3 + _t4
Goto _L1
_L0: _t5 = x * y;
z = _t5 + z;
_L1:Three adress Control Flow Graph (CFG)
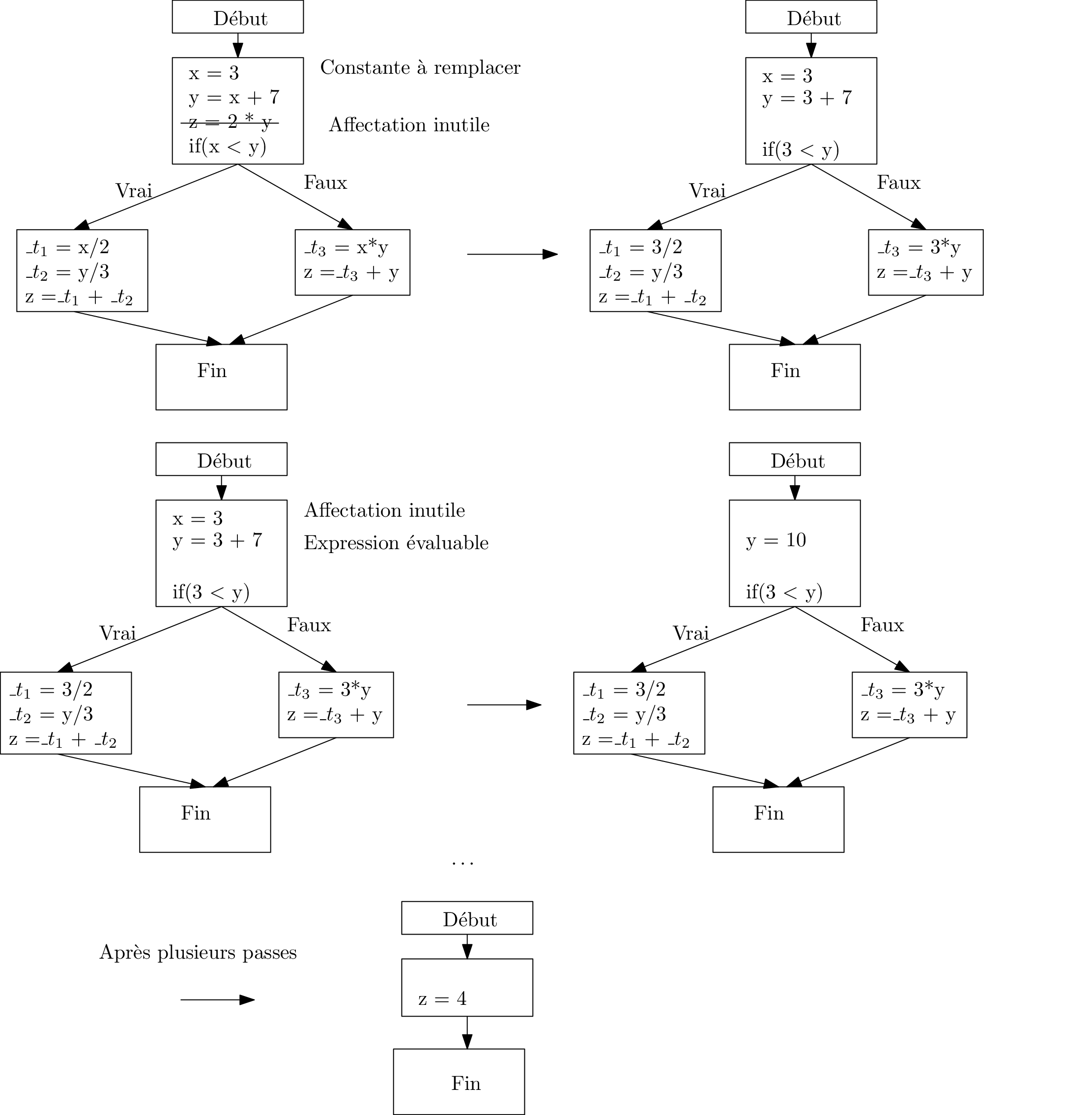
Optimisation d’un CFG
Note
Application répétée de quelques règles de simplification
- supprimer des affectations inutiles
- remplacer des constantes : int x = 3; int y = x + 2 ⇒ int x = 3 ; int y = 3 + 2;
- calculer des expressions constantes : int y = 3 + 2; ⇒ int y = 5
jusqu’à ce que plus aucune des règles ne soit applicable
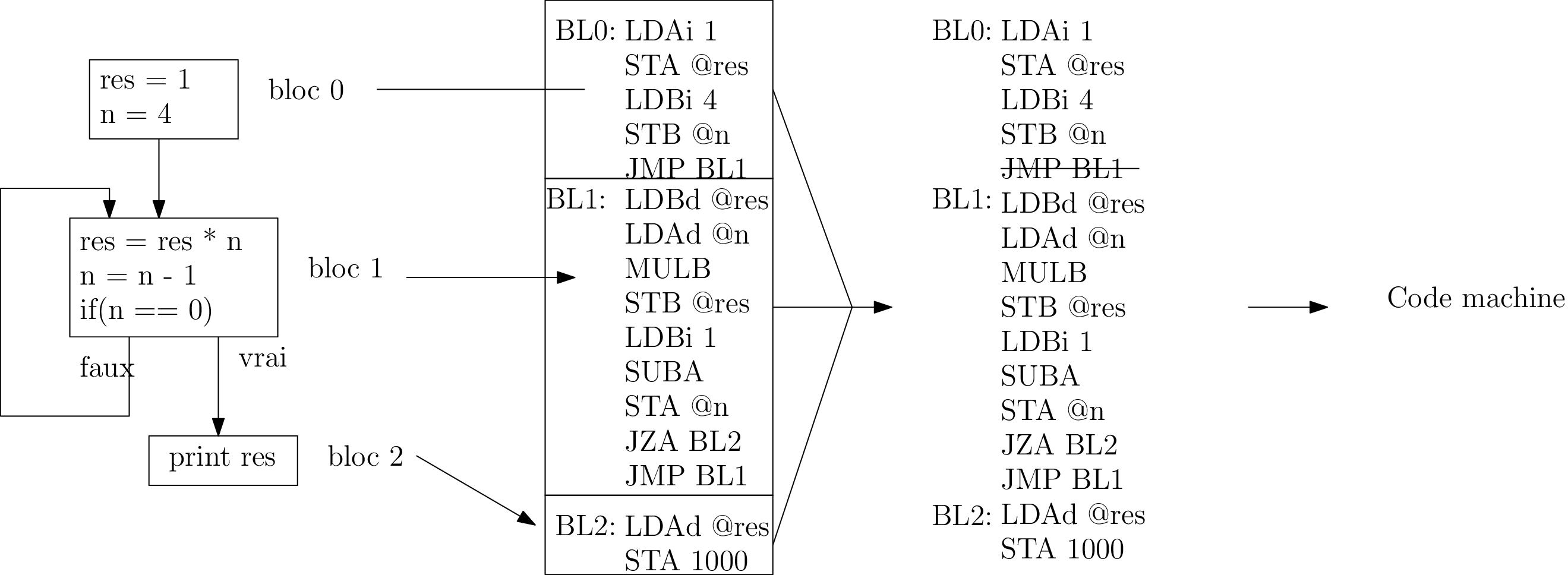
La phase de synthèse (backend)
Représentation intermédiaire ⇒ Code machine
- génération du code machine de chacun des blocs
- disposition en mémoire des blocs
- optimisations éventuelles
Et voila
Références :
- “The dragon book” Aho, Lam, Sethi, Ullman
- “Modern Compiler Implementation”, A. Appel
Comment faire pour simplifier la programmation ?
Ne plus écrire en code machine1
2000 0002
3000
LDBi 2
ADDA
b=2
a=a+b
et bien sûr comment faire la conversion vers le langage machine