L’écosystème python est très riche en librairies scientifiques :
Numpy pour le calcul,
Pandas pour l’analyse de données,
Scipy pour le traitement du signal,
Scikit-learn pour l’apprentissage automatique,
Matplotlib/Seaborn pour les tracés,
Sympy pour le calcul symbolique,
Introduction à l’interpréteur python
Les interpréteurs
Python est un langage interprété
Langage compilé = déjà transformé en instructions CPU
Langage interprété = un programme (compilé :) ) transforme “à la volée” votre code en instructions.
“à la volée”: cpython peut créer un fichier .pyc qui contient le code compilé (bytecode).
fix_jer@stollen:~$ python3Python 3.8.10 (default, May 26 2023, 14:05:08)[GCC 9.4.0] on linuxType"help", "copyright", "credits" or "license" for more information.>>> l = range(100)>>> sum(l)4950>>>
Les interpréteurs
Le plus connu, de l’inventeur du langage, Guido Van Rossum : CPython
import numpy as npl = np.arange(10000000)lsum = l.sum()
Un autre bénéfice de la compilation : le code vectorisé
Instructions vectorielles
les processeurs modernes disposent d’instructions vectorielles, e.g. AVX
une instruction vectorielle (SIMD : Single Instruction Multiple Data) peut appliquer la même opération sur plusieurs données (e.g. \(4\) données)
l’interpréteur python CPython ne supporte pas les instructions vectorisées,
les compilateurs, e.g. pour C++ comme gcc ou clang, réorganisent le code pour exploiter les instructions SIMD
les outils/librairies comme numpy, cython ou pypy compilent du code python et peuvent utiliser les instructions SIMD
Installation des packages
Environnement virtuel
Un environnement virtuel est :
un répertoire isolé d’installation
qui a vocation à ne contenir que les dépendances de votre projet en cours
dont la construction est documentée
Il permet la reproductibilité (Benureau and Rougier 2018), avec le contrôle des packages installés et de leurs versions.
Différentes options :
venv (inclus dans Python depuis la version 3.3) : python package manager, ne permet pas de changer de version de python
anaconda, miniconda, mamba, micromamba, etc… : system package manager. Permet de changer de version de python, installer des dépendances autres que des packages python (e.g. C++, Java, Rust, …), mais parfois un peu lourd
uvhttps://docs.astral.sh/uv : python package manager, flexible sur la version de python, ne permet d’installer que des paquets python
Exemple avec micromamba
Pour installer micromamba (en utilisateur normal):
$"${SHELL}"<(curl-L micro.mamba.pm/install.sh)
Pour construire un environnement virtual local dédié :
$ uv pip install numpy pandas matplotlib$ uv pip install numpy==2.0.1$ uv pip install -r requirements.txt$ uv pip install . # pour un projet avec un pyproject.toml par exemple
Environnement de développement
VS Code
Warning
Vous devez utiliser un Integrated Development Environment (IDE)
Suggestion : utilisez Visual Studio Code + tout son environnement de plugins qui permet :
de gérer votre projet (création, organisation des fichiers)
disposer de la coloration syntaxique, complétion de code, etc…
mettre en place un environnement virtuel et exécuter le code dans cet environnement
branchements conditionnés if ... else ..if ... elif ... else
opérateur ternaire, lambda fonction
syr =lambda x: x//2if x%2==0else2*x+1x =18syr(x)
boucles for x in [1, 2, 3]:, while condition:
Rappels de syntaxe de base
Sur les listes
l = [1, 2, 3]# Listes par compréhensionl2 = [li**2for li in l]lpair = [li for li in l if li %2==0]# Slicing, indexationl[start:step:stop]# E.g. : inversionl[::-1]
Faire attention aux constructions du type :
l = .... # une séquencelsum =0for i inrange(len(l)): lsum += l[i]
Complexité en temps en \(O(|L|^2)\) pour une liste chaînée. Complexité en temps en \(O(|L|)\) pour un tableau.
Rappels de syntaxe de base
Les générateurs
Une construction de liste par compréhension est exécutée à la déclaration.
Pour économiser de la mémoire (e.g. permettant de représenter d’énormes structures), on peut utiliser des générateurs
l = [i**2for i inrange(10000000)] # Liste créée tout de suitelsum =sum(l)# Avec des générateursl = (i**2for i inrange(10000000)) # Liste créée tout de suitesum(l)
Rappels de syntaxe de base
Sur les fonctions
Définition d’une fonction : def fname():
# Une fonction à 3 argumentsdef f(a, b, c): ....return ...f(1, 2, 3)
On peut utiliser un nombre variable d’arguments positionnels *args et/ou nommés **kwargs (kwargs = keyword arguments). Voir Python args and kwargs.
@your_decoratordef say_hi(name):print("Hi ! My Name is "+ name)def your_decorator(func):def wrapper(*args,**kwargs):# Do stuff before func... result = func(*args,**kwargs)# Do stuff after func..return resultreturn wrapper
@CountCallNumberdef say_hi(name"): print("Hi ! My Name is "+ name)class CountCallNumber:def__init__(self, func):self.func = funcself.call_number =0def__call__(self, *args, **kwargs):self.call_number +=1print("This is execution number "+str(self.call_number))returnself.func(*args, **kwargs)
Rappels de syntaxe de base
Loguer avec print: Pour déboguer un programme, on utilise bien souvent des print(...)
Que l’on peut combiner avec des f-strings :
def sqsum(l: list):returnsum((li**2for li in l))l = [1, 2, 3]print(f"La somme des carrés de {l} est : {sqsum(l)}")
import mathp = math.pi# Produit un label de longueur 10, avec pi arrondi au millièmepilabel =f"La valeur de pi arrondi au millième est {math.pi:10.3f}"print(pilabel)
Loguer avec logging : On peut aussi utiliser des loggers du module logging :
withopen("monfichier", "r") as fh:whileTrue: line= fh.readline()if line =='':break process(line)# Ou avec walruswithopen(fname, 'r') as fh:while((line:=fh.readline()) !=''): process(line)
Ecriture :
withopen("monfichier", "w") as fh: montexte =f"La valeur de pi arrondi au millième est {math.pi:10.3f}" fh.write(montexte)
ATTENTION C’est une très mauvaise idée de stocker en ASCII des données numériques.
La valeur “1.23439949959” en ASCII occupe \(13 \times 8 = 104 bits\). Alors qu’un flottant peut occuper \(64\), \(32\), \(16\) bits.
Si ce sont des tableaux de valeurs, utilisez numpy.savez.
Vous pouvez aussi construire votre propre format de fichier et utiliser fh.seek(), fh.read(num_bytes), struct.pack(), struct.unpack(). Voir [struct](https://docs.python.org/3/library/struct.html]
Sur des formats spécifiquesyaml, xml, json, utilisez des parsers écrit pour le yaml, xml, json
Python: classes, threads, UI, packing
Un problème pour se motiver
Problème Simuler un système d’Ising (Sethna (2006), Hayes (2000)). Moment magnétique des atomes arrangés sur une grille régulière \(\sigma_i \{-1, 1\}\). Pour une grille finie, il existe un nombre fini de configurations mais avec des dynamiques intriguantes.
La probabilité d’occuper un état du système \(\sigma\) est \(P(\sigma) = \frac{1}{Z}\exp(-\beta E(\sigma))\), avec
import setuptoolswithopen("README.md", "r") as fh: long_description = fh.read()setuptools.setup( name="Ising", version="1.0", author="CentraleSupelec", author_email="Jeremy.Fixcentralesupelec.fr", description='A simulator of the Ising model with ''the Metropolis algorithm', long_description=long_description, long_description_content_type="text/markdown", url='http://tutos.metz.centralesupelec.fr/Intro_Python', packages=setuptools.find_packages(), classifiers=["Programming Language :: Python :: 3","License :: OSI Approved :: MIT License","Operating System :: OS Independent", ], python_requires='>=3.6', install_requires=['numpy', 'scipy', 'PyQt5', 'matplotlib', 'opencv-python-headless'])
Et vous pourriez déposer votre librairie sur pypi, ou conda.
Calcul scientifique avec Numpy
Introduction
Numpy : Numerical Python
Librairie C++ avec un wrapper python,
qui offre des tableaux multi-dimensionnels et des opérations optimisées
NumPy is the fundamental package for scientific computing in Python. It is a Python library that provides a multidimensional array object, various derived objects (such as masked arrays and matrices), and an assortment of routines for fast operations on arrays, including mathematical, logical, shape manipulation, sorting, selecting, I/O, discrete Fourier transforms, basic linear algebra, basic statistical operations, random simulation and much more.
à partir d’une liste (éventuellement de listes de listes de ..)
à partir de fonctions dédiées : np.zeros, np.ones, np.arange, np.linspace, np.random.rand, etc.
à partir de fichiers : np.loadtxt, np.genfromtxt, np.load, etc.
# Tableau 1D de taille (5, )np.array([1, 2, 3, 4, 5])# Tableau 2D de taille (2, 3)np.array([[1, 2, 3], [4, 5, 6]])# Tableau 2D de taille (3, 4) rempli de zérosnp.zeros((3, 4))# Tableau 6D de taille (2, 3, 4, 5, 6, 7) rempli de unsnp.ones((2, 3, 4, 5, 6, 7))# Tableau 1D de 0 à 10 par pas de 2np.arange(0, 10, 2)# Tableau 1D de taille (5, ) avec des valeurs entre 0 et 1np.linspace(0, 1, 5)# Tableau 2D de taille (3,3) avec des valeurs aléatoires entre 0 et 1np.random.rand(3, 3)
Propriétés des tableaux
Les tableaux ont :
une forme (shape) : nombre de dimensions et taille dans chaque dimension,
un type (dtype) : type des éléments du tableau,
un nombre d’éléments (size) : nombre total d’éléments dans le tableau,
un nombre de dimensions (ndim) : nombre de dimensions du tableau.
a = np.array([[1, 2, 3], [4, 5, 6]])print(a)print("Shape:", a.shape) # (2, 3)print("Dtype:", a.dtype) # int64 (ou int32 selon la plateforme)print("Size:", a.size) # 6print("Ndim:", a.ndim) # 2
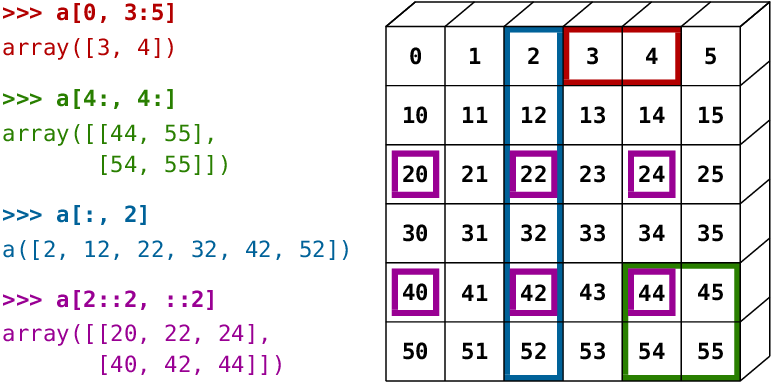
Accès aux éléments
On accède aux éléments :
par index,
par slicing, en utilisant la syntaxe python start:stop:step,
a = np.array([[1, 2, 3], [4, 5, 6]])# Accès par index# Premier élément de la première lignea[0, 0] # 1# Accès par slicing# Deuxième ligne# Equivalent à a[1]a[1, :] # [4 5 6]# Première colonnea[:, 0] # [1 4]# Toutes les lignes, colonnes d'indice paira[:, ::2] #a[:, ::2] =0# Modifie a# Masquage booléen : fancy indexingmask = a >3# np.array de dtype boolb = a[mask] # [4 5 6]b[0] =10# Ne Modifie pas a
Accès aux éléments (suite)
Ne jamais faire
a = np.array([[1, 2, 3], [4, 5, 6]])for i inrange(a.shape[0]):for j inrange(a.shape[1]): a[i, j] =0
mais utiliser l’ellipsis :
a = np.array([[1, 2, 3], [4, 5, 6]])a[...] =0
Manipulations sur la forme des tableaux
On peut modifier la forme d’un tableau par :
np.reshape : retourne une vue du tableau avec une nouvelle forme,
np.flatten ou np.ravel : retourne une copie ou une vue du tableau aplati (1D),
np.transpose : retourne une vue du tableau transposé,
np.pad : ajoute une bordure autour du tableau.
np.expand_dims, x = x[np.newaxis, :] : ajoute une nouvelle dimension.
On peut combiner/diviser plusieurs tableaux par :
np.concatenate : concatène plusieurs tableaux le long d’un axe,
np.stack : empile plusieurs tableaux le long d’un nouvel axe,
np.hstack et np.vstack : concatène horizontalement ou verticalement plusieurs tableaux.
np.split, np.hsplit, np.vsplit : divise un tableau en plusieurs sous-tableaux.
On peut permuter les éléments d’un tableau par :
np.transpose, np.swapaxes
np.roll
Opérations arithmétiques sur les tableaux
Les opérations arithmétiques sont appliquées élément par élément +, ‘/’, -, *. Il existe également les opérations logiques.
a = np.array([[1, 2, 3], [4, 5, 6]])b = np.array([[10, 20, 30], [40, 50, 60]])# Addition c = a + b # [[11 22 33] [44 55 66]]# Soustractiond = b - a # [[9 18 27] [36 45 54]]# Multiplication terme à termee = a * b # [[10 40 90] [160 250 360]]# Division terme à termef = b / a # [[10. 10. 10.] [10. 10. 10.]]
Attention : * est le produit terme à terme, pas le produit matriciel. Le produit matriciel est obtenu par np.matmul ou simplement @
Illustration - Système de GrayScott
Problème Simuler le système de réaction-diffusion de GrayScott dont l’évolution des champs spatialisés \(u(x,t)\), \(v(x,t)\), \(x\in \mathbb{R}^2\) est régie par :
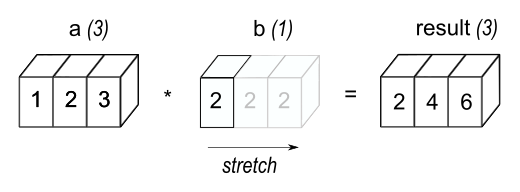
La règle : des opérations sur deux tableaux sont applicables si les dimensions sont compatibles.
Les dimensions sont compatibles si, 1) les tableaux ont le même nombre de dimensions, 2) partant de la droite (des dimensions)
les dimensions sont égales
ou sont différentes mais l’une d’elle est égale à \(1\)\(\rightarrow\) Broadcast
Sinon vous obtiendrez l’exception ValueError: operands could not be broadcast together
Broadcasting - example
Par exemple, on souhaite calculer la valeur d’une fonction gaussienne \(f(x)\) centrée en \(\mu\in\mathbb{R}^2\), sur une grille régulière centrée sur \(\mu\) :
if__name__=='__main__': mu = np.array([1, 2]) sigma =0.3 step =0.1 Nsteps =10 X = gaussian(mu, sigma, step, Nsteps)def gaussian(mu: np.ndarray, sigma: float, step: float, Nsteps: int) -> np.ndarray:# Generate the regular grid# (-N, -(N-1), ..., -1, 0, 1, ..., N-1, N) * step intsteps = (np.arange(Nsteps) +1) deltasteps = np.concatenate([-intsteps[::-1], [0], intsteps]) * step# Generate the steps centered on mu# mu is (2, ), we use broadcasting on mu and deltasteps to generate# mu (2, 1) + deltasteps(1, M) => mu + deltasteps is (2, M) mu_delta = mu[:, np.newaxis] + deltasteps[np.newaxis, :]# Generate the meshgrid with this values# X and Y are of shape (2*Nsteps + 1, 2*Nsteps + 1) X, Y = np.meshgrid(mu_delta[0], mu_delta[1])# Concatenate the X, Y matrices# xy is (( (2*Nsteps + 1) * (2*NSteps + 1), 2) xy = np.concatenate((X.ravel()[:,np.newaxis], Y.ravel()[:, np.newaxis]), axis=1)# Compute tha gausian values# To compute the distance between the grid points is computed between xy and mu# To broadcast, we do : xy (M, 2) - mu(1, 2) dist = ((xy - mu[np.newaxis, :])**2).sum(axis=1) values =1.0/ (2.0* sigma * np.sqrt(2.0* np.pi)) * np.exp(- dist / (2.0* sigma**2))# Values is of shape (( (2*Nsteps + 1) * (2*NSteps + 1), ) that we reshape as # (2*Nsteps + 1, 2*Nsteps + 1) values = values.reshape((2*Nsteps +1, 2*Nsteps +1))return values
Algèbre linéaire
Numpy supporte bien évidemment toutes les routines utiles en algèbre linéaire, dans le sous-package np.linalg:
produit matriciel , matrice-vector : np.dot
calcul de la trace np.linalg.trace,
calcul de l’inverse : np.linalg.inv, du déterminant np.linalg.det
calcul des normes : np.norm - norme \(p\) pour un vecteur \((\sum_i x_i^p)^{1/p}\), Frobenius pour une matrice,
En fonction du range de \(A\), il peut exister une infinité de solution. Si \(A\) est singulière, une solution est obtenue en résolvant le problème des moindres carrés régularisés \(argmin_x J(x) + \lambda \|x\|_2^2\) , \(\lambda \in \mathbb{R}^+\) :
\[
x = (A^T A + \lambda \mathbf{I})^{-1} A^T b
\]
Avec numpy :
import numpy as npdef rls(A: np.ndarray, b: np.ndarray, lbd: float) -> np.ndarray: n, m = A.shape inv = np.linalg.inv(A.T@A + lbd * np.eye(m)) x = np.dot(inv@A.T, b)return xif__name__=='__main__': n, m =3, 4 A, b = np.random.random((n, m)), np.random.random((n,)) lbd =0.001 x = rls(A, b, lbd)print(x)
Algèbre linéaire - PCA
Analyse en composantes principales Soit \(N\) vecteurs \(x_i \in \mathbb{R}^d\), trouver le vecteur \(w_0 \in \mathbb{R}^d\) et \(r\) vecteurs de projections \(w_j\) qui minimisent l’erreur de reconstruction :
class PCA:def fit(self, X):''' Performs the PCA of X and stores the principal components. The datapoints are supposed to be stored in the row vectors of X. It keeps only the n_components projection vectors, associated with the n_components largest eigenvalues of the covariance matrix X.T X '''# Center the datapointsself.centroid = np.mean(X, axis=0)# Computes the covariance matrix sigma = np.dot((X -self.centroid).T, X -self.centroid)# Compute the eigenvalue/eigenvector decomposition of sigma eigvals, eigvecs = np.linalg.eigh(sigma)# Note :The eigenvalues returned by eigh are ordered in ascending order.# Stores the n_components eigenvectors/eigenvalues associated# with the largest eigen values#self.eigvals = eigvals[-self.n_components:]#self.eigvecs = eigvecs[:, -self.n_components:]# Stores all the eigenvectors/eigenvalues# Useful for later computing some statistics of the variance we keepself.eigvals = eigvalsself.eigvecs = eigvecsdef transform(self, Z):''' Uses a fitted PCA to transform the row vectors of Z Remember the eigen vectors are ordered by ascending order Denoting Z_trans = transform(Z), The first component is Z_trans[:, -1] The second component is Z_trans[:, -2] ... '''return np.dot(Z -self.centroid, self.eigvecs[:, -self.n_components:])
Analyse de données avec pandas
Introduction
La librairie pandas est développée pour l’analyse de données.
une série peut être indexée, slicée, etc.. comme un tableau numpy avec iloc, et comme un dictionnaire avec [..] ou loc()
une DataFrame est une collection de séries de données (comme une base de données)
d = {"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),"two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),"three": pd.Series([1.0, 2.0 ], index=["b", "d"])}df = pd.DataFrame(d)print(df) one two three a 1.01.0 NaN b 2.02.01.0 c 3.03.0 NaN d NaN 4.02.0df.loc['a',['one', 'three']] # pd.Series
on accède aux colonnes df.columns, à leurs types df.dtypes, à l’index df.index
on peut ajouter (comme un dictionnaire) des colonnes df["four"] = df["one"] + df["two"], supprimer del df["one"]
Créer une dataframe et obtenir des infos
On peut construire une DataFrame à partir de dictionnaires, tableaux numpy, … ou de fichiers :
Important fixer les types des séries permet de profiter de toutes les fonctionnalités associées (e.g. catégories, temps)
Calculer des statistiques descriptives
Sur une dataframe, on peut :
calculer des moyennes, sommes, médianes : df["Age"].median()
agréger avec une liste de fonctions prédéfinies (min, max, mean, …) ou arbitraires df.agg({"Age": ["min", "max", "median", "skew"]})
Les statistiques peuvent être calculées sur des sous-groupes formés par groupby:
titanic = pd.read_csv("data/titanic.csv")# On peut regrouper les données par catégories et calculer# des statistiques sur les sous-groupestitanic = pd.read_csv("titanic.csv") grouped = titanic[["Sex", "Pclass", "Age", "Fare"]].groupby(["Sex", "Pclass"])print(grouped.size())print(grouped.mean())
PassengerId Survived Pclass ... Fare Cabin Embarked0103 ... 7.2500 NaN S1211 ... 71.2833 C85 C2313 ... 7.9250 NaN SSex Pclassfemale 1942763144male 112221083347dtype: int64 Age FareSex Pclass female 134.611765106.125798228.72297321.970121321.75000016.118810male 141.28138667.226127230.74070719.741782326.50758912.661633
Partant d’une représentation empilée (stacked), on peut réarranger les données avec la méthode pivot ou pivot_table (permet d’agréger) :
index : la ou les colonnes qui servent d’index
columns : les valeurs que ces colonnes prennent deviennent les colonnes
values : les valeurs à l’intersection des valeurs d’index et des valeurs de colonnes
df = pd.DataFrame( {"A": ["one", "one", "two", "three"] *6,"B": ["bidule", "machin", "truc"] *8,"C": ["foo", "foo", "foo", "bar", "bar", "bar"] *4,"D": np.random.randn(24),"E": np.random.randn(24),"F": [datetime.datetime(2013, i, 1) for i inrange(1, 13)]+ [datetime.datetime(2013, i, 15) for i inrange(1, 13)], })print(df)pivoted = pd.pivot_table(df, values="D", index=["A", "B"], columns=["C"])print(pivoted)print(pivoted.loc[("one", "bidule"), "bar"])
A B C D E F0 one bidule foo 0.0295770.0509842013-01-011 one machin foo -0.442099-0.1060082013-02-012 two truc foo 1.9530531.2656772013-03-013 three bidule bar -1.2999820.7620932013-04-014 one machin bar 0.652348-0.3233862013-05-015 one truc bar 1.433064-1.8184662013-06-016 two bidule foo 2.291547-0.0875072013-07-017 three machin foo -1.203084-0.0893232013-08-018 one truc foo 1.022026-1.0884632013-09-019 one bidule bar -0.4337582.8922092013-10-01...C bar fooA B one bidule 0.243642-0.317265 machin -0.183342-0.318656 truc 0.9423411.991506three bidule -0.641189 NaN machin NaN -1.362425 truc -1.088678 NaNtwo bidule NaN 1.272628 machin -0.686480 NaN truc NaN 1.0242240.24364165912866229
pivot retourne une erreur en cas de doublons (moins flexible). pivot_table agrège les doublons (e.g. défaut : aggfunc='mean').
Joindre des tables
On peut joindre plusieurs dataframes par des clés, e.g. :
une table définit des campagnes de mesures avec leurs dates, l’opérateur, etc…
une table contient des observations, associées à un identifiant de campagne de mesures
Ces tableaux peuvent être joints, par exemple pour lister les observations réalisées par un opérateur.
Le tout étant pipelinable et disposant d’une interface commune.
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegression# Chargement des donnéesiris = load_iris()X, y = iris.data, iris.target# Construction d'un pli d'entrainement et un pli de testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)# Construction du prédicteur et entrainementclf = make_pipeline(StandardScaler(), KNeighborsClassifier(3))clf.fit(X_train, y_train)# Evaluation du risque sur un pli de testscore = clf.score(X_test, y_test)# Inférence sur le pli de testy_test_pred = clf.transform(X_test)
Benureau, Fabien C. Y., and Nicolas P. Rougier. 2018. “Re-Run, Repeat, Reproduce, Reuse, Replicate: Transforming Code into Scientific Contributions.”Frontiers in Neuroinformatics Volume 11 - 2017. https://doi.org/10.3389/fninf.2017.00069.
Sethna, James P. 2006. “Statistical Mechanics: Entropy, Order Parameters, and Complexity, 2nd Edition, Chap 8.” In Oxford Master Series in Physic. Univ. Press.